

Voici le 2e article d’une (probable) longue série à propos de l’informatique ! Je pense qu’il est important de faire de la vulgarisation sur ce sujet car l’informatique régit notre vie de tous les jours, certains ne se rendent pas bien compte à quel point. Le but de cette série d’articles est de comprendre certaines bases qui nous touchent tous, comme pour le premier : « pourquoi mon disque dur / clé usb a toujours une capacité réelle plus petite que sur l’étiquette ? ».
Dans cet article-ci on va voir une des très importantes composantes de ce domaine, la sécurité, trop souvent négligée (la sécurité de nos données personnelles etc). En effet, vous envoyez un message sur Messenger ? Il sera stocké sur les serveurs de Facebook, et, à moins que vous fassiez appel à la RGPD, il y sera toujours dans 10 ans. Mais ce n’est pas le cas si vous faîtes une « conversation privée » ou si vous utilisez Whatsapp (qui appartient à Facebook aussi). Ce genre de détails est très important ! Pourquoi ? Simple image avec un exemple de l’actualité d’il y a quelques mois : demandez à Griveaux ce qu’il en pense ! Alors en effet cette fuite-là n’est probablement pas issue de Facebook, mais c’est surtout pour montrer les impacts que certaines personnes mal intentionnées peuvent faire avec vos données de tous les jours – et oui vous avez des choses à cacher, d’autant plus que c’est sans prendre en compte l’avenir encore une fois (les mœurs tout comme les lois évoluent).
Quelle est la différence entre une conversation privée Messenger/Whatsapp et une discussion « normale » ? Un équivalent de l’HTTPS est mis en place, une technique qu’on appelle plus spécifiquement : le chiffrement asymétrique. On va commencer par la théorie en voyant ce que c’est plus en détails, ne vous inquiétez pas ce n’est rien d’incroyablement compliqué !
Qu’est-ce que le chiffrement asymétrique ? Un peu d’histoire et de théorie
En informatique (et ça s’applique aussi en dehors), il existe deux manières de chiffrer une information ou une donnée : « l’asymétrique » et le « symétrique ». Alors déjà pour commencer, vous l’aurez constaté, on parle de chiffrement et pas de cryptage, mais bon je reconnais que c’est être « grammar-nazi » (ce que je suis, enfin quand ça m’arrange… bref). Je vais rapidement expliquer les deux, en quoi ils consistent et leurs différences dans cette partie. Rassurez-vous ça restera compréhensible pour le commun des mortels, du moment que vous ayez quelques bases en maths et encore.
Pourquoi c’est important de chiffrer le plus possible, sur Internet ou ailleurs
Avant de commencer, rapidement, quel est l’intérêt de chiffrer une information ? C’est pour empêcher qu’un tiers (une autre personne qui aurait accès à votre échange) ne puisse comprendre quoi que ce soit. Historiquement ça a surtout été utilisé pour des affaires militaires, pour qu’au cas où le message ait été intercepté il ne puisse pas être compris, ou en tout cas à temps. En effet le messager portant le message était à cheval donc interceptable bien sûr. Ensuite il passait par télégraphe ou par radio, qui sont eux aussi interceptables évidemment, maintenant c’est par sms, 4G et/ou internet, ça ne change rien à la problématique !
Le chiffrement symétrique
Le chiffrement symétrique c’est la manière de faire la plus simple (c’est pour ça que je commence par ça) : vous passez votre donnée à travers une « clé » qui la transforme, clé connue seulement de l’émetteur et du receveur pour que ce dernier puisse retrouver le message original, mais évidemment inconnue des tierces personnes. C’est la même clé utilisée par les deux acteurs de l’échange. L’exemple le plus simple et le plus « historique » pour le comprendre c’est le « chiffrement de César », qui aurait été apparemment utilisé par Jules César donc (ça date !). C’est le plus simple que l’on puisse faire : la « clé », c’est de décaler les lettres de quelques positions dans l’alphabet.
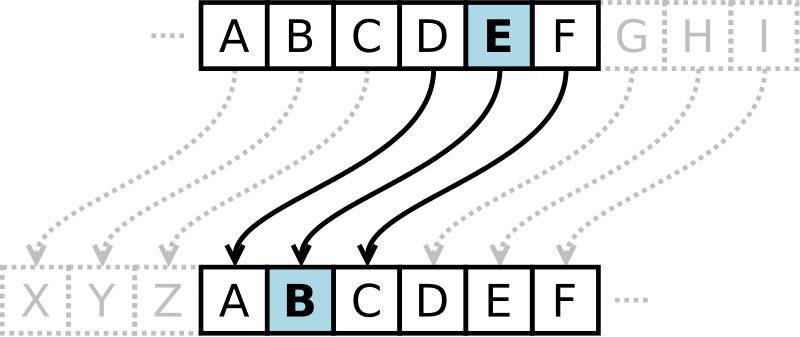
Un autre exemple très connu : la machine Enigma utilisée par l’Allemagne durant la seconde guerre mondiale. En quoi ça consistait ? En fait c’était un décalage de César mais qui changeait pour chaque lettre (y compris pour la même lettre deux fois à la suite !) et chaque jour. Il était mis en place à travers un fonctionnement complexe mécanique de différents rotors et configuré par une clé, elle aussi mécaniquen renseignée au départ (en gros le réglage des différents rotors composant la machine). Cette clé avait environ 159 milliards de milliards de possibilités. Car oui évidemment il y a une sorte de course à la complexité dans ce domaine, qu’on appelle la cryptographie (le terme « cryptomonnaies » en est issu d’ailleurs).
En effet si vous faîtes un simple chiffrement de César, il suffit d’essayer les 25 combinaisons possibles de décalage pour finir par tomber sur le message envoyé… Ce n’est pas très compliqué. Admettons que je sois parano et que je contacte ma maîtresse pour savoir quand se « rencontrer » et que ma femme intercepte… ou lis mes sms (dans le but de nous prendre sur le fait), par exemple « tgpfgb-xqwu eg uqkt ». La première chose qu’elle essaiera de faire c’est peut-être de décaler d’une lettre ou deux pour voir si ça ne tombe pas sur un mot de la langue Française… et là je serais mal ! (Essayez-vous aussi c’est facile, indices : essayez d’abord de trouver les lettres présentes plusieurs fois et décalez en arrière).
L’Enigma était donc bien plus complexe, bien évidemment dans le but d’essayer d’assurer une bien meilleure sécurité. C’est à dire en faisant en sorte que le « craquage » à la main en essayant toutes les possibilités mettent des mois ou des années, pour qu’un message intercepté soit inutile, car obsolète. Dans l’idée c’était bien parti car il y avait 159 milliards de milliards de possibilités donc.
Mais au final ça n’a pas empêché qu’elle soit « craquée » par les Alliés durant la guerre, grâce à l’apparition de l’informatique, au vol physique d’une machine et au fait que les Allemands envoyaient toujours « Heil Hitler » au début de certains messages (pour la météo du jour de mémoire), permettant d’aider à deviner la configuration pour la journée (la clé). C’est ça la vraie cryptographie, l’art de trouver comment décrypter un message sans pour autant y aller en mode bourrin en essayant toutes les combinaisons possibles (ce qu’on appelle communément le « brute-force »).
En informatique c’est donc la même chose. Le problème, c’est que nos machines actuelles sont très puissantes : 159 milliards de milliards de possibilités ça se craque en un jour et quelques sur un supercalculateur actuel ! Rappelez-vous que l’informatique a été utilisée pour craquer l’Enigma, à l’époque un ordinateur faisait la taille d’une salle et pouvaient faire peut-être une opération par seconde, alors que là j’ai pris l’exemple du 50e supercalculateur mondial en 2017 (qui est en France, à 3 millions de milliards par seconde).
On est donc toujours dans cette course mais elle a pris des proportions énormes en 50 ans. Le chiffrement symétrique est particulièrement vulnérable au brute-force, parce que c’est en fait une simple fonction (dans le sens mathématique : f(x) ). Bon de nos jours les algos actuels (fiables) changent complètement le « rendu », il peut y avoir plusieurs lettres chiffrées pour une seule réelle etc. La grosse problématique surtout c’est qu’il faut trouver un moyen pour communiquer la clé à son pair sans la passer « en clair » avant, car sinon le « tiers espion » pourra la voir aussi (et c’est pourtant comme ça que fonctionnaient les premiers chiffrements de WiFi… Comme le WEP qui était encore commun durant le début des années 2010 !).
Bref, c’est principalement pour répondre à ces lacunes que le chiffrement asymétrique a vu le jour !
Le chiffrement asymétrique
Alors par contre le chiffrement asymétrique est vachement plus complexe à conceptualiser/comprendre. Je rappelle que c’est ça qui est utilisé pour l’HTTPS et la plupart des modes de communication de ce genre, où l’émetteur et le receveur ne se connaissent pas forcément - ou en tout cas pas à l’avance (quand vous allez sur un site il ne vous connaît pas et vous non plus). Ça permet d’éviter tout bonnement la grosse problématique de l’échange de clés.
En fait dans le cadre de l’asymétrique, il y a 2 clés. Chaque acteur en possède 2 différentes (on peut donc dire qu’il y en a 4 par communication). En effet chacun possède une clé dite « publique » qui sert à chiffrer, et une clé « privée » qui elle sert à déchiffrer. Ainsi, l’émetteur chiffre son message avec la clé publique du récepteur (et vice-versa) et ce dernier déchiffre le message avec sa propre clé privée.
La clé publique comme son nom l’indique est accessible par tous, mais ça ne permet pas à un tiers malintentionné de comprendre un message échangé car il a besoin de la clé privée correspondante pour le déchiffrer (qui est générée en fonction de la clé publique mais c’est presque impossible de la retrouver ! (je dis « presque » car rien n’est absolument impossible dans ce domaine)). Voilà, c’est assez complexe et honnêtement je n’ai pas les compétences mathématiques pour comprendre comment ça fonctionne réellement, je ne sais pas vous, mais ça fonctionne, la preuve avec l’HTTPS donc !
Ce système n’a qu’un seul défaut : tout le monde peut chiffrer les données comme l’émetteur, ainsi il est possible de faire du brute force à ce niveau : chiffrer plein de possibilités jusqu’à arriver à tomber sur le même résultat (ce qui est passé dans le réseau – internet, wifi etc), on sait alors ce qui a été envoyé. Bien évidemment c’est quasi impossible à faire sur un forum par exemple ou sur whatsapp car le contenu de votre message peut autant avoir 1 caractère ou 5 000 avec des chiffres etc… Ou encore être une image qui comprend des millions d’octets (des Mo quoi) ! C’est impossible de savoir la taille ou le type du message (enfin avec cette seule information, ce genre d’infos peuvent se trouver autrement), ainsi le nombre de possibilités est évidemment énorme.
Par contre ça peut se faire sur par exemple les mots de passe de banques qui sont souvent une sélection de 6 à 8 chiffres, là il n’y a alors « que » 10 puissance 8 possibilités ! (10 chiffres possibles 8 fois, soit 100 millions. Ce n’est pas tant que ça, 30 secondes pour notre super calculateur). Heureusement les banques (ou ceux qui ont fait leurs sites) le savent, dans la réalité les chiffres envoyés sont en fait eux-mêmes chiffrés par autre chose et on ne les envoie pas directement. Pensez à l’interface pour saisir les nombres, ils changent de position à chaque essai etc donc il y a une forme d’aléatoire ici - en tout cas pour les banques que j’utilise, vous pouvez le vérifier vous-même en allant dans l’onglet « réseau » après avoir appuyé sur F12 (sur un navigateur sur PC), vous pouvez voir ce que vous envoyez au serveur de la banque, ça devrait être différent à chaque saisie alors même que vous envoyez le même mot de passe.
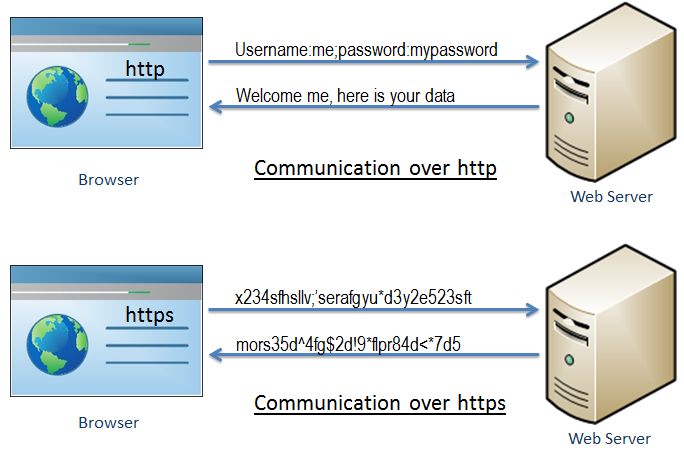
Je termine cette partie par des images explicatives pour comparer les deux méthodes (source des images it-connect.fr) :
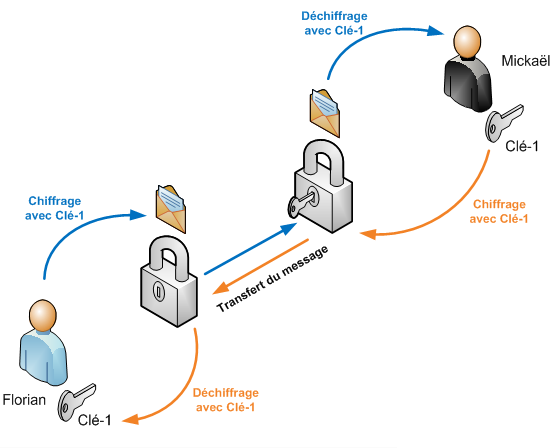
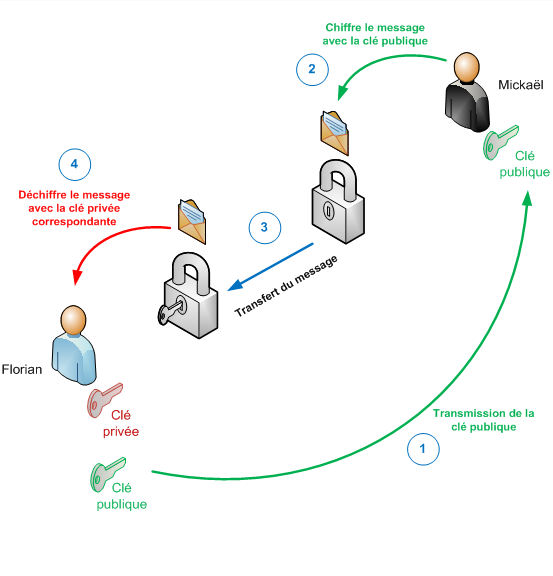
De quoi l’HTTPS protège dans les détails alors ?
Ça y est on a fini la théorie ! Ça va vous suivez toujours ? Revenons au sujet de l’article, au final j’ai moins de choses à dire ici par rapport aux méthodes de chiffrement. Je vais présenter un cas concret utilisé par tous dans la vie de tous les jours, l’HTTPS sur le web !
Rapide introduction sur le fonctionnement d’Internet
Pour comprendre de quoi l’HTTPS protège, il faut d’abord voir rapidement comment internet fonctionne.
Tout d’abord pour être « connecté », vous devez être relié (par wifi, par 4G ou par câble par exemple) vers un routeur, ou ce qu’on appelle communément une box. Jusque-là vous suivez j’espère ! Or le wifi ou la 4G sont des ondes émises dans toutes les directions que n’importe qui à proximité peut intercepter en théorie. Heureusement les protocoles wifi/4G implémentent eux-mêmes des méthodes de chiffrement pour éviter l’interception des données en clair qui transitent (qui elles-mêmes peuvent ensuite être chiffrées à travers HTTPS ou non). Mais à noter que l’on découvre assez souvent des failles exploitables, donc ce maillon n’est clairement pas le plus sûr (quand c’est des failles côté hardware les FAI ne viennent pas changer toutes leurs box dans toute la France pour les corriger, donc plein de gens gardent pendant des années des matériels « vérolés », c’est heureusement un peu plus « safe » côté 4G je pense mais évidemment rien ne vaut le câble).
Ensuite, les requêtes que vous envoyez à un site et leurs réponses transitent à travers internet, qui peut être littéralement compris comme le « réseau de réseaux ». Pour faire simple, vos échanges vont passer à travers d’autres routeurs, c’est eux qui font internet, comme ceux de votre fournisseur internet ou ceux d’autres pays (par exemple en Chine tout est contrôlé par le gouvernement).
Enfin, pour accéder à un site et un article précis sur ce site, vous faîtes appel à son URL (l’équivalent d’une adresse postale, on va dire). L’URL est comprise de différentes parties qu’il nous faut différencier. Prenons l’url de l’article sur la taille des disques dur : https://super.support-vision.fr/articles/pourquoi-les-disques-durs-cles-usb-ont-toujours-une-capacite-reelle-47 . Deux parties de l’url nous intéressent ici : d’abord « super.support-vision.fr », indique le nom du site (autrement appelé le « domaine »), le reste à droite « /articles/pourquoi-les-disques[…] » indique au site quel article est demandé. Si on peut faire une comparaison rapide, l’article demandé correspond à un fichier (c’est comme au chemin dans un ordinateur) et le domaine indique sur quel ordinateur on veut récupérer ce fichier.
Voilà en gros comment fonctionne le web de manière très simplifiée !
Qu’est-ce que l’HTTPS « cache » ? Quand est-il particulièrement utile ?
La réponse est simple : l’HTTPS protège tout sauf le domaine (le nom du site). Il cache toute l’url ainsi que tout ce qui est envoyé dans une requête (comme des mots de passe), sauf la partie correspondante au domaine donc, car des routeurs/proxy tiers peuvent avoir besoin du domaine pour savoir quoi faire/relayer etc. Ainsi il ne cache pas le site que vous visitez, par contre il cache la page que vous consultez. Et ne vous cache surtout pas du point de vue de ce site, qui lui verra tout passer en clair évidemment.
C’est quelque chose qui me semble assez méconnu, mais oui le propriétaire du serveur va évidemment savoir que vous avez consulté x page à y heure peu importe que vous soyez en HTTPS ou non (il va voir votre adresse IP avec vos cookies qui sont envoyés à chaque requête : pour certains sites ça permet de vous suivre à la trace, pour d’autres comme le mien ici non, car l’adresse IP seule n’est pas suffisante). D’ailleurs c’est quelque chose qui peut aussi être connu par l’hébergeur dudit site (mais ça dépend de la configuration serveur, la tendance est à ça en tout cas, je pense notamment aux clouds Microsoft, Amazon ou Google où c’est quelque chose d’assez commun…).
Donc l’HTTPS vous protège d’un Wifi public ouvert (n’entrez jamais un mot de passe sur ce genre de wifi si le site est seulement en HTTP !), de votre employeur ou FAI et potentiellement n’importe quel tiers qui vous attaque/cible en écoutant vos communications (virus sur l’ordinateur, NSA, état Français (si si) etc). Par contre attention je me répète, votre employeur par exemple peut toujours savoir sur quel site vous êtes, or si vous êtes sur p*rnhub il n’a pas besoin de savoir quelle vidéo vous regardez précisément pour comprendre que vous faîtes autre chose que bosser ! (Ne faîtes pas ça hein !). Voilà vous savez tout.
Les prochains articles de cette série vont détailler le fonctionnement d’Internet bien plus précisément, autant pour les « moldus » que pour les geeks. N’hésitez pas à vous abonner sur les réseaux sociaux pour ne pas les louper !